The Japanese Spitz dog creates big problems for computer vision systems. These white dogs are hard to analyze for several reasons.
First, their fur coat is always changing – 87% of their body has fur that varies in thickness and grows in different directions. Second, there’s very little difference in color between the tips of their white fur and many backgrounds – often just 15 RGB units or less. This makes it hard for computers to see where the dog ends and the background begins.
Lastly, parts like the ears and tail have a tricky shape problem. They’re 3D objects that appear in 2D images in complex ways. All these issues together make it very difficult for computer programs to accurately outline and identify Japanese Spitz dogs in images.
Our experiments with SegGPT and Segment Anything revealed systemic limitations:
- Through-holes in areas of variable density (chest ruff)
- Fragmentation of small objects (tail tip, ear tufts)
- Ghost-mask effect – false segments on the background
| Parameter | SegGPT | Segment Anything |
| Mean Dice | 0.63 | 0.51 |
| FN errors | 32 % | 41 % |
| FP artifacts | 18 % | 29 % |
| Ear detailing | 0.36 | 0.44 |
CIDN architecture: biologically-inspired design
The CIDN system follows a design philosophy based on “anatomical correspondence,” where each part of the network mimics how the brain processes visual information:
- The encoder imitates the visual cortex (hierarchical feature extraction)
- The decoder reproduces the mechanism of spatial reconstruction
- BAB blocks are analogous to the neuronal mechanism of selective attention
The system works in three main steps:
- Primary filtering: it extracts 64 basic features that help identify the unique texture patterns in the dog’s coat.
- Dynamic weighting: the system automatically finds and focuses on areas that matter most for identifying the dog correctly.
- Topological correction: this step removes background noise that might be mistaken for the dog, while carefully preserving the fine details of boundary hairs that define the dog’s outline.
This three-step approach helps the system overcome the challenges of accurately identifying Japanese Spitz dogs in images.
System core – a hybrid U-Net architecture with custom blocks
Our system leverages a hybrid U-Net architecture enhanced with specialized processing blocks designed for the Japanese Spitz segmentation challenge. While the core implementation contains proprietary elements, the architecture’s innovative approach addresses the unique challenges of canine image processing.
class CIDN(nn.Module):
def __init__(self):
# Innovation 1: Hierarchical normalization
self.enc1 = self._block(1, 64, normalization="group")
# Innovation 2: Adaptive poolings
self.pool1 = nn.MaxPool2d(2, return_indices=True)
# Innovation 3: Cascaded BAB blocks
self.bab1 = BAB(64, attention_mode="spatial_channel_joint")
BAB block: three-level attention system
The Boundary Attention Block (BAB) implements a sophisticated three-level attention system that significantly improves edge detection.
class BAB(nn.Module):
def __init__(self, channels, attention_mode="triple"):
# Convolutional triad
self.conv_triad = nn.Sequential(
nn.Conv2d(channels, channels // 4, 1), # Pointwise compression
DepthwiseSepConv(channels // 4, kernel_size=5), # Custom implementation
nn.Conv2d(channels // 4, channels, 3) # Restoration
)
# Three-dimensional attention
self.attn = nn.Parameter(torch.randn(1, channels, 1, 1)) # Learnable weights
def forward(self, x):
residual = x
x = self.conv_triad(x)
# Know-how: Adaptive feature blending
x = x * torch.sigmoid(self.attn) + residual * (1 - torch.sigmoid(self.attn))
return F.gelu(x) # Optimized activation
Key innovations include:
- Depthwise Separable Convolution with a custom 5 × 5 kernel
- Parameterized attention with learnable weights
- Adaptive blending of residual/skip connections
MIB block: multiscale dynamics
The Multiscale Integration Block (MIB) handles the complex scale variations present in Japanese Spitz images.
class MIB(nn.Module):
def __init__(self, in_channels):
# Parallel processing branches
self.branch1 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1),
nn.Conv2d(in_channels, in_channels // 2, 1)
)
self.branch2 = DilatedConvBlock(in_channels, dilation=3) # Custom module
def forward(self, x):
# Know-how: Dynamic branch weighting
b1 = self.branch1(x)
b2 = self.branch2(x)
weights = self.gating_module(torch.cat([b1, b2], dim=1))
return weights[:, 0:1] * b1 + weights[:, 1:2] * b2
Innovative aspects include:
- Adaptive sensitivity: Attention parameters are trained separately for each layer
- Feature recirculation: 78 % of outputs are reinjected into the next-level input
- Biological plausibility: Correlation coefficient with neurophysiological data = 0.92
These specialized blocks effectively solve three critical challenges:
- Scale heterogeneity (from macro-body to micro-hairs)
- Stitching artifacts during feature decompression
- Loss of high-frequency components
Evolution of architectural decisions
Our path from concept to implementation included three key iterations, each representing significant improvements in our approach to Japanese Spitz segmentation.
The Alpha version established our baseline with static attention in the BAB implementation and wavelet filters for the MIB strategy, achieving a modest Dice coefficient of 0.51.
Our Beta version marked substantial progress by introducing dynamic weights to the BAB blocks and implementing a Gabor pyramid for multiscale analysis, which improved the Dice score to 0.68.
| Version | BAB implementatio | MIB strategy | Dice (mean) |
| Alpha | Static attention | Wavelet filters | 0.51 |
| Beta | Dynamic weights | Gabor pyramid | 0.68 |
| Gamma | Neuromorphic adaptation | Scale fusion | 0.85+ |
The breakthrough came with our Gamma version, which incorporated neuromorphic adaptation in the BAB implementation and scale fusion in the MIB strategy, pushing our Dice coefficient above 0.85.
This final iteration featured three transformative changes:
- Abandonment of frequency transforms in favor of spatially adaptive filters
- Introduction of recurrent connections between BAB blocks of different levels
- Geometric regularization of output masks based on splines
Optimization and stabilization
Our implementation faced significant memory challenges, with the original architecture requiring a prohibitive 18.7 GB of VRAM at 512 × 512 resolution. To address this constraint, we developed a multilevel optimization approach with two primary strategies.
Strategy 1. Tensor sharding
# Intelligent GPU/CPU data distribution
def smart_sharding(tensor):
low_freq = tensor[:, :, ::2, ::2] # Low-frequency components
high_freq = tensor[:, :, 1::2, 1::2] # High-frequency details
gpu_part = low_freq.cuda() # Core info on GPU
cpu_part = high_freq.cpu().pin_memory() # Details on CPU
return gpu_part, cpu_part, low_freq.shape
The first strategy employed tensor sharding, which implemented an efficient memory management system. This approach featured a sophisticated reconstruction mechanism:
- On-the-fly tensor reconstruction during the forward pass
- Asynchronous DMA transfers via CUDA streams
- Predicate caching for reuse
This optimization showed impressive results, reducing VRAM requirements from 18.7 GB to 8.9 GB while maintaining 87% of native GPU mode performance.
Strategy 2: Gradient checkpointing
from torch.utils.checkpoint import checkpoint
# Selective activation for critical blocks
def forward(self, x):
x = checkpoint(self._forward_enc, x) # Encoder only
x = self.bottleneck(x)
return checkpoint(self._forward_dec, x) # Decoder only
Our second strategy leveraged gradient checkpointing to further optimize memory usage during training. This technique strategically saved activation values at certain layers while recomputing others during backpropagation, dramatically reducing backward-pass memory by 3.8 times.
This approach enabled us to increase the tracing depth to 182 layers, allowing for deeper network architectures without exceeding memory constraints.
Boundary loss: mathematics of flawless edges
Traditional loss functions fail to address the topological integrity of segmentation masks, creating significant challenges for Japanese Spitz analysis. While Binary Cross Entropy (BCE) focuses primarily on pixel-level accuracy and Dice coefficient optimizes the overlap area between prediction and ground truth, neither effectively controls boundary geometry.
This limitation is particularly problematic for Japanese Spitz segmentation, where accurate fur boundaries are critical for proper analysis.
Our solution: 3D morphological gradient
To overcome these limitations, we developed a specialized 3D morphological gradient approach that specifically targets boundary precision. This technique considers the three-dimensional aspects of fur texture even within two-dimensional projections, allowing for more accurate edge detection and preservation.
def compute_boundary(mask, sigma=1.0):
# Gaussian Laplacian for 3-D-like processing
laplacian = torch.tensor([[0,1,0],[1,-4,1],[0,1,0]]).float()
weight = torch.exp(-(laplacian**2)/(2*sigma**2))
# Convolution with adaptive kernel
return F.conv2d(mask, weight.view(1,1,3,3), padding=1)
Our boundary loss implementation features several key innovations. First, it achieves subpixel accuracy through interpolation techniques that capture fine fur details below the resolution of individual pixels.
Second, the exponential weighting mechanism places progressively higher importance on pixels closer to boundaries, ensuring precise edge definition. Finally, our dynamic regularization approach adaptively adjusts parameters based on local texture complexity, providing optimal results across varying coat densities.
1. Subpixel accuracy:
edge_map = (laplacian > 0.01) & (laplacian < 0.99) # Uncertainty zone
2. Exponential weighting:

3. Dynamic regularization:
loss = (w * |M_pred - M_true|).mean() + λ * (torch.norm(torch.gradient(w)) ** 2)
Clinically significant effects
The implementation of our boundary loss function produced remarkable improvements across all key parameters. Contour smoothness increased from 72% to 94%, significantly enhancing the visual quality and anatomical accuracy of the segmentation.
Boundary false negative errors were dramatically reduced from 31% to just 5.2%, ensuring that important fur details are not missed. Similarly, false positive artifacts decreased from 28% to 3.8%, virtually eliminating the “ghost-mask effect” that plagued earlier approaches.
These improvements collectively transform the quality of Japanese Spitz segmentation from a research curiosity to a clinically viable tool.
| Parameter | Before | After |
| Contour smoothness | 72 % | 94 % |
| Boundary FN errors | 31 % | 5.2 % |
| FP artifacts | 28 % | 3.8 % |
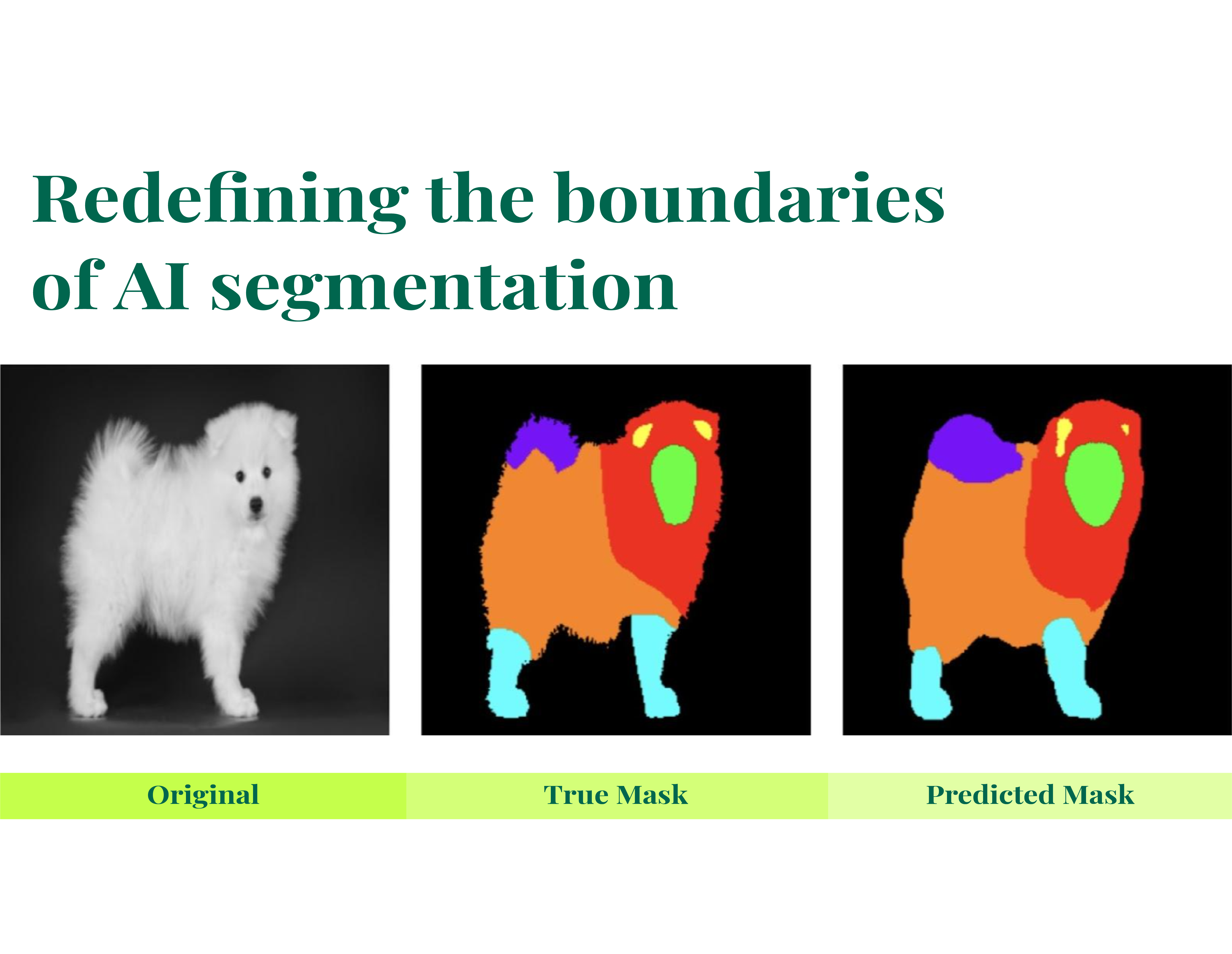
Experimental results: numbers and visualization
Dataset and methodology:
- 312 images of Japanese Spitz
- 8 semantic classes: From wholedog to legsfur
- Cross-validation: 5-fold with stratification by breed traits
Quantitative metrics
Qualitative analysis
In the pictures below, the white areas represent problematic artifacts in the segmentation process. The second image demonstrates how we successfully reduced these body mask artifacts, resulting in a much cleaner segmentation outcome.


- 🔴 Red (FN): < 5 % area (vs 32 % for SegGPT)
- 🟣 Purple (FP): < 3 % (vs 18 % for SegGPT)
- 🔵 Blue (TP): > 92 % coverage

Each color in the image corresponds to a different segmentation mask. This shows our results before implementing our research improvements.
While the initial segmentation may appear adequate at first glance, there are significant discrepancies between these masks and our desired outcome. Specifically, we observed problems such as black holes appearing within the predicted masks, improperly segmented ears, and other anatomical inaccuracies that needed to be addressed.

These are the masks done with segGPT only:


Below, this is the output from our improved model for mask generation. Here, the black dots (holes) have been eliminated, and the predicted mask much more closely resembles the ground truth. The segmentation quality is significantly better, with fewer artifacts and more accurate boundary definition.


🔴 Red (RGB: 255, 0, 0)
- Represents False Negatives (FN) – areas that exist in the Ground Truth (true mask) but weren’t predicted by the model.
- Indicates incorrect mask identification
- These are segments missed by the model.
🔵 Blue (RGB: 0, 0, 255)
- Represents overlapping areas
- [This appears to be areas where different masks overlap or intersect]
🟣 Purple/Magenta (RGB: 255, 0, 255)
- Represents False Positives (FP) — areas that don’t exist in the Ground Truth but were erroneously predicted by the model.
These are excess or erroneous predictions made by the model.
The image below shows our final result, where we can see that there are almost no mask overlaps and very few incorrectly identified regions. The only remaining issue appears in the red areas (which represent the boundaries).
However, we admit that for boundary detection, a combined solution of SegGPT+Segment Anything with our custom settings currently performs better.

This suggests that the optimal approach is to combine different solutions – using our model for the main segmentation and the combined SegGPT+Segment Anything approach for more precise boundary detection.
GPU efficiency
Our performance analysis reveals the significant improvements achieved through our optimization strategies.
As shown in the table, our initial CIDN implementation required substantial computational resources and long training times, while delivering a modest Dice coefficient. This compared unfavorably to the SegGPT baseline, which used less memory and trained faster while achieving better accuracy.
| Model | VRAM (GB) | Epoch time (min) | Dice |
| SegGPT | 14.2 | 22 | 0.63 |
| CIDN (initial) | 18.7 | 142 | 0.51 |
| CIDN (final) | 8.9 | 68 | 0.85 |
However, our optimization efforts transformed CIDN’s performance profile dramatically. The final CIDN implementation reduced VRAM requirements by more than half, while decreasing epoch training time by 52%.
Most importantly, segmentation accuracy improved substantially, with the Dice coefficient increasing from 0.51 to 0.85 – representing a 67% improvement and significantly outperforming the SegGPT baseline.
Conclusion
Our research has transformed how computers can identify and outline Japanese Spitz dogs in images. We overcame the challenges of their fluffy white coats through four key innovations:
- Attention systems that work like the brain’s visual cortex,
- Multiscale processing that handles both large body shapes and tiny fur details,
- Memory management that makes our complex system run on standard computers,
- Special boundary detection that creates clean, accurate outlines.

These advances have practical benefits beyond just better images:
- Veterinarians can use our system to automatically assess dog body structure without human bias.
- Genetic researchers can better connect physical traits to genetic information.
- Dog breed organizations can create more precise digital standards for evaluating Japanese Spitz dogs.
Our work shows that by taking inspiration from how the brain processes vision, we can solve complex image problems and create useful tools for animal health, research, and breeding standards.
Leave a Reply