When humans judge image quality of animals like the Japanese Spitz, it seems highly subjective. Traditional computer vision tries to solve this by training deep neural networks on labeled data.
The hope? That models will somehow grasp the concept of “beauty.” But this approach misses something crucial. Human perception isn’t a blank slate – it’s a sophisticated tool shaped by millions of years of evolution.
We propose a different hypothesis: modern aesthetic judgment is an exaptation. This means an old adaptation developed for one purpose now serves a new function. When we admire a Spitz’s fluffy fur or clear eyes, we’re using ancient visual attention mechanisms.
These mechanisms originally evolved to quickly assess health, strength, and potential threats in the wild. Our brain doesn’t see a “picture” – it processes visual signals through filters that highlight survival-relevant information.
This insight changes our approach. Instead of hunting for data correlations, we need reverse engineering. We must reconstruct how visual signals transform in the human brain.
This means modeling hierarchical filters where each stage discards 90% of information as “noise” while passing the significant 10% to the next level.
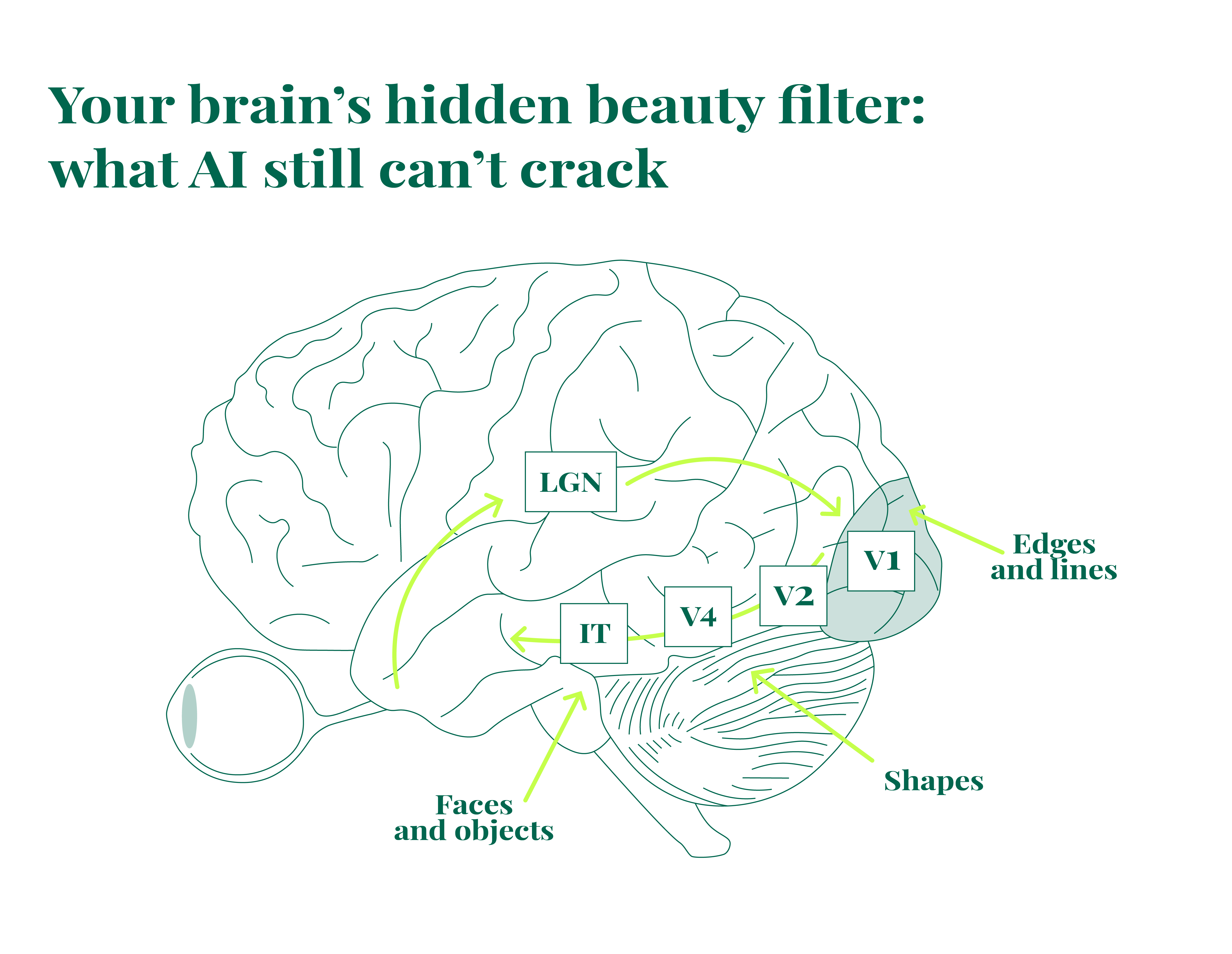
Our work aims to create a computational visual saliency model based on primate visual pathways. The model follows biological structures – from retinal low-level feature detection to semantic analysis in the ventral stream.
We believe only such a bio-inspired approach can reliably predict aesthetic image scores by addressing the root causes of perception rather than surface features.
We first explore the theoretical groundwork, examining how the human visual system processes aesthetic information through evolutionary mechanisms. This will be followed by a practical implementation guide, where we translate these biological principles into functional algorithms for predicting subjective image quality assessment.
Brain’s visual processing pipeline
The human visual system works like a sophisticated processing pipeline, with each component handling specific visual transformations. To model this system properly, we need to understand what each part does.
Level 0. The retina – your first line of visual processing
Visual processing starts in your eyes, not your brain. The retina isn’t just a simple camera sensor – it’s a complex computational organ with multiple neuron layers.
Ganglion cells are the key players here, with their axons forming the optic nerve. These cells don’t send “raw pixels” to your brain. Instead, each one detects specific patterns in a tiny visual area, functioning like dedicated hardware accelerators for critical visual tasks:
Contrast detectors (ON-center/OFF-surround and vice versa). These cells fire strongly when their receptive field’s center is brighter than its surroundings (ON-center), or the opposite (OFF-center). Evolution designed this to instantly highlight contours and object boundaries.
For our ancestors, a contour might mean a branch edge or a predator’s silhouette. In a Japanese Spitz photo, these same detectors respond to the boundary between light fur and dark nose, eye sparkles, or ear-to-background transitions.
Motion detectors. Some ganglion cells specifically detect movement in particular directions. These trigger ancient reflexes like “freeze,” “flee,” or “attack.” While inactive in static photos, their existence highlights a key principle: the brain prioritizes changes over static elements.
Center-periphery organization. Cones (for color and detail) are densest in the fovea’s center, while rods (for light sensitivity) dominate the periphery. This creates a natural “map of importance” before information even reaches the brain – the center automatically gets priority for detailed analysis.
💡 Our approach’s philosophy. We mirror this hardware-level optimization in our model. Rather than analyzing the full-color image directly, we first convert it to grayscale and apply mathematical operators (like the Laplacian) that function similarly to ON/OFF ganglion cell receptive fields, highlighting those fundamental contrasts.
Level 1. Primary visual cortex (V1) – breaking down shapes
After leaving the retina, visual signals travel through the optic nerve to the primary visual cortex (V1). V1 neurons are organized with incredible precision and function as detectors of simple features:
- Simple cells: These fire when they detect dark or light lines/edges with very specific orientations in particular locations. Different cells specialize in different angles – vertical, horizontal at 15°, diagonal at 45°, and so on. This represents the next level of abstraction: the brain assembles basic geometric patterns from the many point contrasts received from the retina.
- Complex cells: These respond to lines of specific orientations without being tied to exact locations within their receptive field. This flexibility allows us to recognize patterns even when objects move slightly.
Evolution designed this level to extract information about shape and orientation from the chaos of contrasts. For our ancestors, a predator’s snarl appeared as a set of vertical and diagonal lines. A tree branch presented as lines with various orientations. When looking at a Japanese Spitz, V1 neurons activate strongly in response to:
- Vertical lines: the contours of upright ears
- Horizontal lines: the mouth line
- Diagonals and curves: the muzzle curves, round eyes, and flowing fur
💡 Our approach’s philosophy. To simulate the activity of simple and complex cells in V1, we use Gabor filters – the most physiologically accurate mathematical tool for this purpose. Their kernel combines a sinusoidal wave within a Gaussian envelope, perfectly modeling how neurons respond to specific spatial frequencies and orientations. By applying these filters at various angles, our model performs the same function as V1: breaking down the image into basic, oriented components.
Level 2. Secondary visual cortex (V2/V4) – assembling textures and objects
Moving up the visual pathway, the secondary visual cortex (V2 and V4) receives input from V1 and integrates this information into more meaningful patterns. These neurons respond to increasingly complex features:
- Corners and illusory contours – allowing your brain to “complete” shapes even when parts are hidden or missing
- Elementary textures – recognizing repetitive patterns like stripes, grains, and speckles. This is where the countless lines and edges that make up fur get processed into the unified quality we perceive as “fluffiness”. V4 neurons also handle color processing and simple geometric shapes.
This is the level of generalization. If V1 sees thousands of strokes, V2/V4 “understand” that this is the texture of fur. If V1 sees a set of curves, V2/V4 can assemble them into the shape of an eye.
💡 Our approach’s philosophy. To model this integration level, we need more sophisticated tools than simple edge detectors. We need mechanisms that can specifically isolate textural information, separating it from shape and lighting information. Band-pass filtering works effectively here (like creating the difference between two Gaussian blurs with different radii). This technique suppresses low-frequency components (smooth light/shadow transitions and overall shape) and high-frequency noise, preserving the mid-frequency information that corresponds to fur texture features.
Level 3. Inferotemporal cortex (IT) – understanding what we see
At the top of the ventral visual pathway (the “what pathwa”) sits the inferotemporal cortex (IT). This region contains neurons tuned to recognize complete objects and their important parts. Research has identified several specialized systems:
- Face-responsive neurons: A dedicated region (the Fusiform Face Area – FFA) activates specifically when seeing faces. This explains our heightened sensitivity to eyes and facial expressions.
- Specialized recognition neurons: The IT cortex contains different areas responsive to bodies, places, and animals – essentially a catalog of visual concepts built through experience.
When these neurons activate, “recognition” happens: “this is a dog,” “this is an eye,” “this is healthy, shiny fur.” This level provides semantic understanding, where all the lower-level features (contours, textures) finally combine into meaningful categories.
The IT cortex also drives top-down attention – if you’re looking for a dog, it “primes” lower visual areas to expect certain patterns.
💡 Our approach’s philosophy. Modeling the IT cortex presents our biggest challenge. Today’s vision-language models, particularly CLIP, offer powerful approximations of this function. CLIP has learned to connect images with text descriptions in a vast multimodal space. By dividing an image into patches and measuring each patch’s semantic similarity to specific text prompts (“dog eyes”, “fluffy fur”), we essentially replicate the IT cortex’s function: identifying and highlighting regions that carry specific semantic meaning – crucial for subjective quality assessment.
How attention works: bottom-up meets top-down
The visual processing path we’ve described (retina → V1 → V2/V4 → IT) primarily represents bottom-up attention. This pathway is stimulus-driven, involuntary, and controlled by physical properties of what we see: contrast, movement, orientation, and unexpected elements.
But humans aren’t just passive observers. Our attention is largely guided by top-down mechanisms – our goals, tasks, expectations, and past experiences. When you’re asked to “evaluate the quality of fur,” your brain sends signals downward through the hierarchy.

These signals enhance processing in specific areas of V2/V4 that handle textures, and in IT cortex regions tuned to the “fur” category. This reflects your predictive brain in action, actively seeking evidence in the visual field to confirm its expectations.
Conclusion
Understanding how our visual system works reveals a fascinating hierarchy of specialized processors, each extracting different levels of meaning from what we see. This biological architecture provides a blueprint for better computer vision systems. By mimicking nature’s design, we can create models that align with human perception rather than merely correlating with human judgments.
In our next article, we’ll translate these neurobiological principles into practical algorithms and code. We’ll show how to implement each processing stage, from edge detection to semantic analysis, creating a system that evaluates images in ways that reflect human aesthetic judgment.
By building technology that mirrors biology, we aim to bridge the gap between subjective human perception and objective computational assessment.
Leave a Reply